![]()




![]()








About
We will merge two datasets
We will merge two datasets using a crosswalk
Covers the 'mergeData' function, and how to use it in the future
Retrieve Datasets
Our example will merge two simple datasets; The first dataset is from the census bureau and the later dataset has spatial data and will match to the first using each respective datatsets' tract attribute.
The First dataset will be obtained from the Census' ACS 5-year serveys.
The Second dataset is from a publicly accessible link: CSA-to-Tract-2010 crosswalk
Get the Principal dataset.
We will use the function we created in the "ACS" article to download the data.
Our download function will use Baltimore City's tract, county and state as internal paramters.
Change these values in the cell below using different geographic reference codes will change those parameters.
| B19001_001E_Total | B19001_002E_Total_Less_than_$10,000 | B19001_003E_Total_$10,000_to_$14,999 | B19001_004E_Total_$15,000_to_$19,999 | B19001_005E_Total_$20,000_to_$24,999 | B19001_006E_Total_$25,000_to_$29,999 | B19001_007E_Total_$30,000_to_$34,999 | B19001_008E_Total_$35,000_to_$39,999 | B19001_009E_Total_$40,000_to_$44,999 | B19001_010E_Total_$45,000_to_$49,999 | B19001_011E_Total_$50,000_to_$59,999 | B19001_012E_Total_$60,000_to_$74,999 | B19001_013E_Total_$75,000_to_$99,999 | B19001_014E_Total_$100,000_to_$124,999 | B19001_015E_Total_$125,000_to_$149,999 | B19001_016E_Total_$150,000_to_$199,999 | B19001_017E_Total_$200,000_or_more | state | county | tract | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NAME | ||||||||||||||||||||
| Census Tract 2710.02 | 1510 | 209 | 73 | 94 | 97 | 110 | 119 | 97 | 65 | 36 | 149 | 168 | 106 | 66 | 44 | 50 | 27 | 24 | 510 | 271002 |
| Census Tract 2604.02 | 1134 | 146 | 29 | 73 | 80 | 41 | 91 | 49 | 75 | 81 | 170 | 57 | 162 | 63 | 11 | 6 | 0 | 24 | 510 | 260402 |
Get the Secondary Dataset
Spatial data can be attained by using the 2010 Census Tract Shapefile Picking Tool or search their website for Tiger/Line Shapefiles
The core TIGER/Line Files and Shapefiles do not include demographic data, but they do contain geographic entity codes (GEOIDs) that can be linked to the Census Bureau’s demographic data, available on data.census.gov.-census.gov
For this example, we will simply pull a local dataset containing columns labeling tracts within Baltimore City and their corresponding CSA (Community Statistical Area). Typically, we use this dataset internally as a "crosswalk" where-upon a succesfull merge using the tract column, will be merged with a 3rd dataset along it's CSA column. Link: CSA-to-Tract-2010 crosswalk
Our Example dataset contains Polygon Geometry information we want to merge over to our principle dataset by matching on either CSA or Tract
| TRACTCE10 | GEOID10 | CSA2010 | |
|---|---|---|---|
| 0 | 10100 | 24510010100 | Canton |
| 1 | 10200 | 24510010200 | Patterson Park N... |
Perform Merge & Save
The following picture does nothing important but serves as a friendly reminder of the 4 basic join types.
Left - returns all left records, only includes the right record if it has a match
Right - Returns all right records, only includes the left record if it has a match
Full - Returns all records regardless of keys matching
Inner - Returns only records where a key match
The final function will perform this union wherever undefined and undefined match.
| B19001_001E_Total | B19001_002E_Total_Less_than_$10,000 | B19001_003E_Total_$10,000_to_$14,999 | B19001_004E_Total_$15,000_to_$19,999 | B19001_005E_Total_$20,000_to_$24,999 | B19001_006E_Total_$25,000_to_$29,999 | B19001_007E_Total_$30,000_to_$34,999 | B19001_008E_Total_$35,000_to_$39,999 | B19001_009E_Total_$40,000_to_$44,999 | B19001_010E_Total_$45,000_to_$49,999 | ... | B19001_013E_Total_$75,000_to_$99,999 | B19001_014E_Total_$100,000_to_$124,999 | B19001_015E_Total_$125,000_to_$149,999 | B19001_016E_Total_$150,000_to_$199,999 | B19001_017E_Total_$200,000_or_more | state | county | tract | GEOID10 | CSA2010 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1510 | 209 | 73 | 94 | 97 | 110 | 119 | 97 | 65 | 36 | ... | 106 | 66 | 44 | 50 | 27 | 24 | 510 | 271002 | 2.45e+10 | Greater Govans |
| 1 | 1134 | 146 | 29 | 73 | 80 | 41 | 91 | 49 | 75 | 81 | ... | 162 | 63 | 11 | 6 | 0 | 24 | 510 | 260402 | 2.45e+10 | Claremont/Armistead |
2 rows × 22 columns
As you can see, our Census data will now have a CSA appended to it.
Interactive
| B19001_001E_Total | B19001_002E_Total_Less_than_$10,000 | B19001_003E_Total_$10,000_to_$14,999 | B19001_004E_Total_$15,000_to_$19,999 | B19001_005E_Total_$20,000_to_$24,999 | B19001_006E_Total_$25,000_to_$29,999 | B19001_007E_Total_$30,000_to_$34,999 | B19001_008E_Total_$35,000_to_$39,999 | B19001_009E_Total_$40,000_to_$44,999 | B19001_010E_Total_$45,000_to_$49,999 | ... | B19001_013E_Total_$75,000_to_$99,999 | B19001_014E_Total_$100,000_to_$124,999 | B19001_015E_Total_$125,000_to_$149,999 | B19001_016E_Total_$150,000_to_$199,999 | B19001_017E_Total_$200,000_or_more | state | county | TRACTCE10 | GEOID10 | CSA2010 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 808 | 195 | 114 | 80 | 49 | 76 | 81 | 26 | 70 | 0 | ... | 31 | 13 | 0 | 15 | 6 | 24 | 510 | 190100.0 | 2.45e+10 | Southwest Baltimore |
| 1 | 698 | 58 | 69 | 131 | 32 | 39 | 26 | 19 | 24 | 32 | ... | 55 | 5 | 34 | 21 | 19 | 24 | 510 | 190200.0 | 2.45e+10 | Southwest Baltimore |
2 rows × 22 columns
Advanced
Intro
The following Python function is a bulked out version of the previous notes.
It contains everything from the above plus more.
It can be imported and used in future projects or stand alone.
Description: add columns of data from a foreign dataset into a primary dataset along set parameters.
Purpose: Makes Merging datasets simple
Services
Merge two datasets without a crosswalk
Merge two datasets with a crosswalk
Show Code
Function Explanation
Input(s):
Dataset url
Crosswalk Url
Right On
Left On
How
New Filename
Output: File
How it works:
Read in datasets
Perform Merge
If the 'how' parameter is equal to ['left', 'right', 'outer', 'inner']
then a merge will be performed.
If a column name is provided in the 'how' parameter
then that single column will be pulled from the right dataset as a new column in the left_ds.
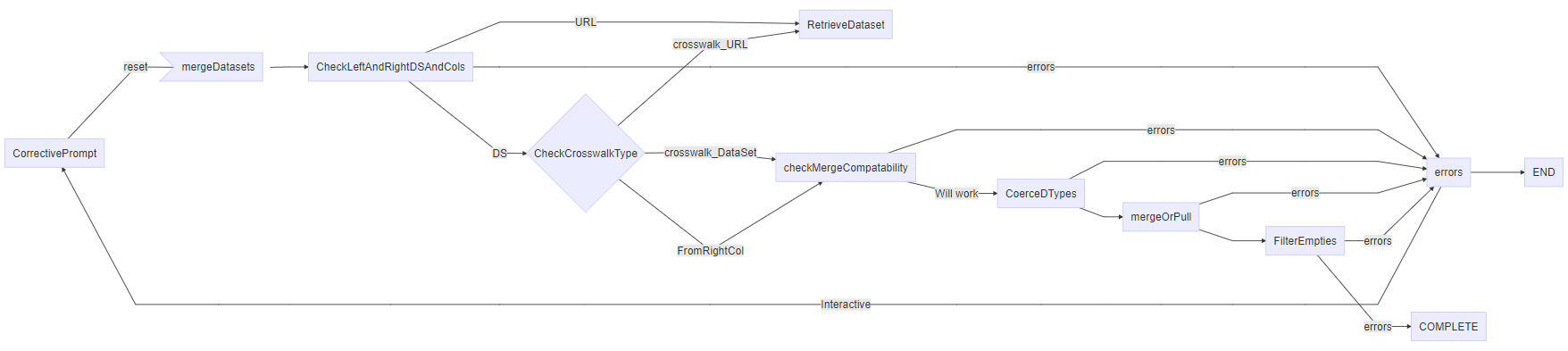
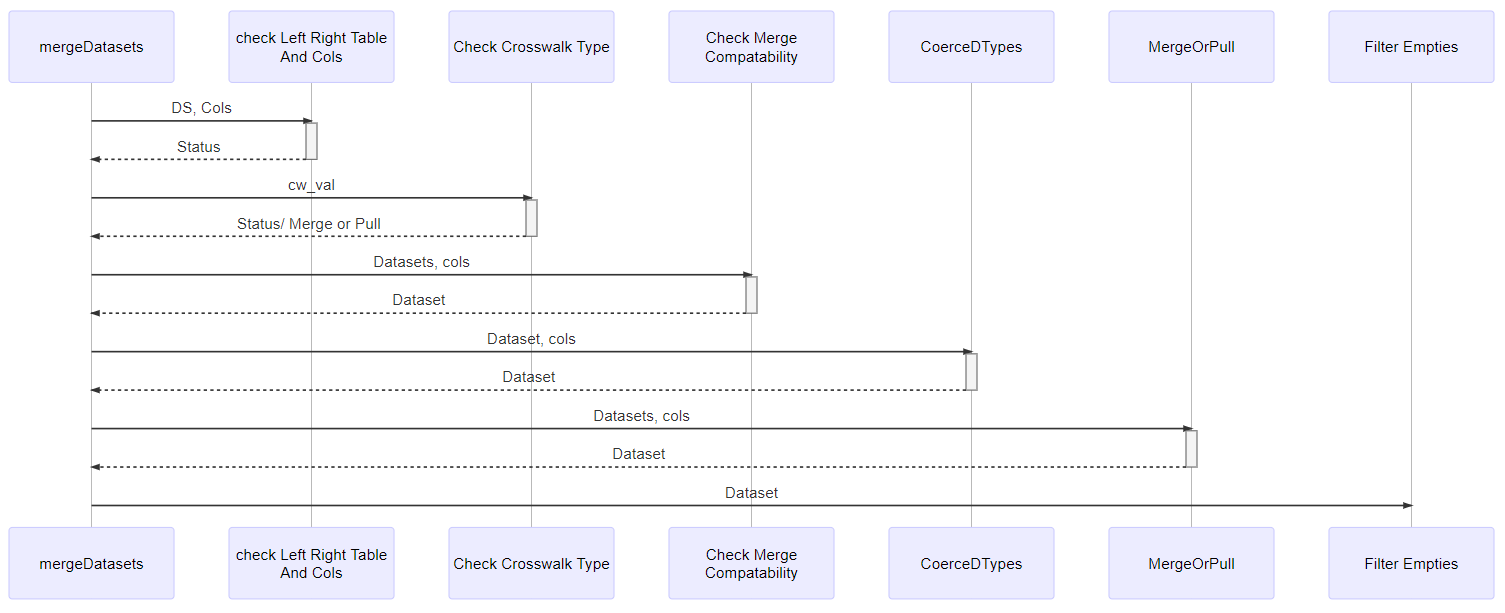
Function Diagrams
Diagram the mergeDatasets()

mergeDatasets Flow Chart
Gannt Chart mergeDatasets()

Sequence Diagram mergeDatasets()
Function Examples
Interactive Example 1. Merge Esri Data
left_ds left_ds| OBJECTID_x | CSA2010 | hhchpov14 | hhchpov15 | hhchpov16 | hhchpov17 | hhchpov18 | hhchpov19 | CSA2020_x | hhchpov20 | ... | hhpov15 | hhpov16 | hhpov17 | hhpov18 | hhpov19 | CSA2020_y | hhpov21 | Shape__Area_y | Shape__Length_y | geometry_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Allendale/Irving... | 41.55 | 38.93 | 34.73 | 32.77 | 35.27 | 32.60 | Allendale/Irving... | 21.42 | ... | 24.15 | 21.28 | 20.70 | 23.0 | 19.18 | Allendale/Irving... | 14.17 | 6.38e+07 | 38770.17 | POLYGON ((-76.65... |
| 1 | 2 | Beechfield/Ten H... | 22.31 | 19.42 | 21.22 | 23.92 | 21.90 | 15.38 | Beechfield/Ten H... | 14.77 | ... | 11.17 | 11.59 | 10.47 | 10.9 | 8.82 | Beechfield/Ten H... | 8.46 | 4.79e+07 | 37524.95 | POLYGON ((-76.69... |
2 rows × 25 columns
Example 2 ) Get CSA and Geometry with a Crosswalk using 3 links
| B19049_001E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Total | B19049_002E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_under_25_years | B19049_003E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_25_to_44_years | B19049_004E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_45_to_64_years | B19049_005E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_65_years_and_over | state | county | tract | |
|---|---|---|---|---|---|---|---|---|
| NAME | ||||||||
| Census Tract 2710.02 | 38358 | -666666666 | 34219 | 40972 | 37143 | 24 | 510 | 271002 |
| B19049_001E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Total | B19049_002E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_under_25_years | B19049_003E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_25_to_44_years | B19049_004E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_45_to_64_years | B19049_005E_Median_household_income_in_the_past_12_months_(in_2017_inflation-adjusted_dollars)_--_Householder_65_years_and_over | state | county | tract | CSA2010 | OBJECTID | hhpov15 | hhpov16 | hhpov17 | hhpov18 | hhpov19 | CSA2020 | hhpov21 | Shape__Area | Shape__Length | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 38358 | -666666666 | 34219 | 40972 | 37143 | 24 | 510 | 271002 | Greater Govans | 20.0 | 21.32 | 19.27 | 19.53 | 17.99 | 20.5 | Greater Govans | 17.19 | 2.27e+07 | 22982.13 | POLYGON ((-76.59... |
| 1 | 44904 | -666666666 | 51324 | 42083 | 37269 | 24 | 510 | 90100 | Greater Govans | 20.0 | 21.32 | 19.27 | 19.53 | 17.99 | 20.5 | Greater Govans | 17.19 | 2.27e+07 | 22982.13 | POLYGON ((-76.59... |